MP-BGP EVPN VXLAN for the beginner

MP-BGP EVPN VXLAN is an overlay network technology that has gained popularity recently due to its ability to provide scalable and efficient network virtualization. This technology combines several protocols, including Multiprotocol Border Gateway Protocol (MP-BGP), Ethernet Virtual Private Network (EVPN), and Virtual Extensible LAN (VXLAN).
As a beginner, it can be overwhelming to understand the details of MP-BGP EVPN VXLAN. However, with the proper guidance and resources, you can adequately master the details. If the reader is unaware of MP-BGP or needs a refresher please read the "MP-BGP for beginners" in the foundational learning path.
We will begin by breaking down the acronyms that make up this long name. First, MP-BGP is a routing protocol that distributes routing information between autonomous systems. Ethernet Virtual Private Network (EVPN) is a Layer 2 VPN technology that extends Layer 2 Ethernet segments over a Layer 3 network. VXLAN is a tunneling protocol used to encapsulate Layer 2 traffic (this is known as an overlay) over a layer 3 IP network (this is known as the underlay). First, we will discuss the Underlay and Overly since they are the most critical pieces.
Underlay/Overlay and VXLAN overview
The most important piece of using this technology is a robust underlay layer 3 IP network with OSPF or BGP routing. Spine-Leaf or Clos-based topology is the recommended layer that distributes underlay. The spine-leaf architecture offers Equal Cost Multipathing (ECMP)three, high Bisectional bandwidth, deterministic reachability, and high redundancy from failure. It is also recommended that the leafs be deployed in pairs using Multiple Link Aggregation Protocol (MLAG) or Virtual Port Channel (vPC) to connect hosts.
The following diagram shows our Spine- Leaf Layer 3 underlay connecting edge devices (leafs) and servers.
The following diagram shows the addition of the Virtual Tunnel Endpoint or VTEP. The VTEP is responsible for encapsulating and de-encapsulating the layer following frames. It can also encapsulate layer two frames and layer three frames, but we will address that later. The VXLAN Identifier or VNI sometimes called the VNIDis the VXLAN identifier. In the bottom diagram, we see three servers are all on VLAN 100. They are all connected to leaf switches which are then connected to layer 3 to the spines and each other. When the servers want to communicate, via layer two, the packet on VLAN 100 is sent to the VTEP encapsulated in VXLAN 10100 and ROUTED to the destination VTEP. The packet is then De-encapsulated and becomes a layer two packet on VLAN 100. That is the simple explanation, but there is more under the covers to be revealed.
The image shows how the encapsulation and de-encapsulation work; when a layer following frame is forwarded to the VTEP (more on how that happens later)two the 802.1Q VLAN tag of VLAN 100 is removed. Then the VXLAN frame is ADDED to the original layer two frames with the 802.1Q header removed. On the destination end, the process is reversed. The VXLAN header is removed, and the 801. Q header of VLAN 100 is replaced, and the frame is sent to its destination. One important thing to note is that every source and destination VTEP MUST have a VNI to VLAN mapping table and MUST be identical across the fabric for proper operations. The mapping on the switches is necessary, so the correct 802.1Q header is replaced on the destination. This mapping function can be altered in the case of brownfield or merging networks with different VLANs. By modifying the mapping, VLAN 100 could be translated to VXLAN 10100 differently; for instance, it could be mapped to VLAN 200 on a brownfield or migration switch.
The Challenges of VXLAN
VXLAN was created with a joint venture of Cisco, Arista, VMWare, and other OEMS in 2011. It was ratified in RFC 4378 in 2014, so it's over ten years old. It has remained on the back burner for many years as there is an inherent problem: Mac address learning on the local switch is not discovered on remote switches. If we look below, we see how a standard layer two network switch operates. Mac addresses are learned, and a mac address table is created with the mac learned and port learned. For Broadcast, Unknown Unicast, and Multicast traffic (BUM), traffic is flooded to all ports except the port of the source mac address.
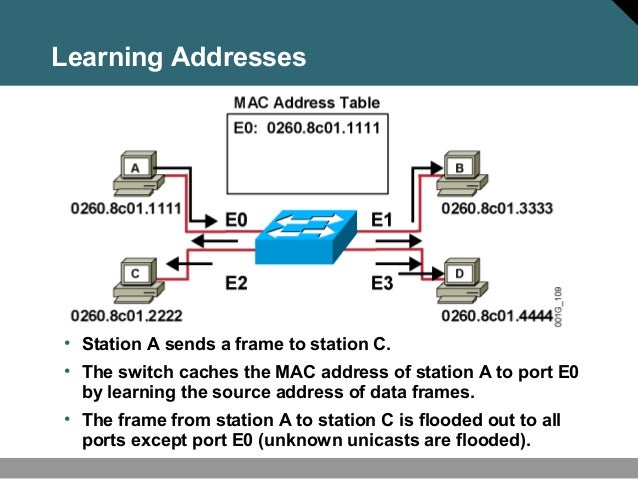
In a standard VXLAN fabric, that traffic had to be flooded with a layer three protocol(multicast) because flooding is a layer two protocol, and VXLAN operates over layer 3. Multicast and Head End Replication (HER) were used but limited the size and scale of VXLAN fabrics, so VXLAN was not widely adopted.
The first VXLAN methodology below is called flood and learn via multicast. Like a regular layer-two switch, the mac address table is consulted for local mac addresses and floods out the layer-two ports like a typical layer-two standard switch. What is different is that this BUM traffic is also VXLAN encapsulated and multicast to all switches in the VXLAN domain. The return traffic mac is then added to the mac address table cache from the VTEP. This process then builds a local and remote Mac Address table, but the remote cache typically times out in 600 sec.
The second methodology uses Head End Replication (HER) to flood the traffic and build the local and remote MAC address tables. Both are inefficient and do not scale well.
VXLAN IRB (Asymmetrical and Symmetrical) and distributed gateways
The VTEP allows us to do VXLAN bridging, as we learned in the previous sections, and it also integrates routing on the VTEP. This integration is called IRB or integrated routing and bridging. IRB allows us to use the same virtual IP and mac addresses for the GW across the fabric. IRB will enable us to route locally on the TOR switch between subnets on the local switch. One critical piece to remember is that in IRB, we route first, then bridge in the traffic via VXLAN. Understanding the route first, then the bridge concept becomes essential when discussing the asymmetrical or direct mode and symmetrical or indirect mode of deploying a VXLAN EVPN fabric.
In Asymmetrical IRB, the forward and return paths differ. In the diagram below, hosts A and C are on different subnets. Using IRB, we route first, then bridge. So traffic from Host A hits SVI 10, then is routed to SVI 30 on Leaf 1A and then bridged on VXLAN 10030 (VLAN30), bridged and reaches Leaf Host C on VLAN 30. The return traffic from Host C routes from SVI 30 to SVI 10 then is bridged over VXLAN 10010 (VLAN 10). Traffic then is sent to Host A via VLAN 10. In this case, the traffic pattern is asymmetrical.
Asymmetric IRB has three significant limitations, Remote learning, VNI scaling, and MAC table explosion. There are also limitations on VRF-based multitenancy as this does not support using multiple VRFs.
In Symmetric IRB, a new L3 ONLY VNI gets created; this VNI requires a new vrf. The existing SVI's must get configured using this VRF; the MP-BGP is also configured with the new VRF, and RD and RT use this new vrf. Only one L3 VNI is required per VRF; if our fabric has 1 VRF, we need 1 VRF->L3VNI mapping; if we have 10 VRFs, we need 10 VRF-> L3VNI mappings.
The traffic flow in Symmetric IRB is similar to the Asymmetric we route first, then bridge to the VNI. In Symmetric IRB, we route first to the new L3 VNI and then bridge across this new VNI as if it were an L2 VNI.
The distributed anycast gateway feature for EVPN VXLAN is a default gateway addressing mechanism that enables using the same gateway IP addresses across all the leaf switches that are part of a VXLAN network. This ensures that every leaf switch can function as the default gateway for the workloads directly connected. The feature facilitates flexible workload placement, host mobility, and optimal traffic forwarding across the VXLAN fabric.
Using MLAG and vPC with the Anycast feature allows the leaf switch pair to appear as one Anycast GW and one switch with two links in a port channel.

MP-BGP-EVPN; a better mousetrap
VXLAN never took off due to the scale issues, and a better way of mac learning and propagation was needed. RFC 7209 was the basis for the research into mac learning for an Ethernet VPN(EVPN). Eventually, RFC 7432 was born, and it uses a new EVPN address family in MP-BGP to advertise the Mac and Mac-IP addresses of devices attached to the leaf switches to the spines and then propagate throughout the fabric. The layer 2 MAC and layer 3 MAC-IP are advertised as reachable in the back of the local VTEP. We still need to flood BUM traffic, but the reduction is 95% or more because we know all of the MAC and MAC-IP and what VTEP they reside behind.
MP-BGP Primer
BGPv4 was designed as an Inter-AS routing protocol between multiple AS (eBGP). However, it is now also used as an Intra-AS routing protocol (iBGP). BGP Speakers are routers that exchange reachability information. BGP uses TCP port 179 for communication, setup, and messaging. The pairing devices (BGP Speakers) create a client-server relationship using TCP. BGP typically requires an underlying IGP routing protocol, such as OSPF, for reachability, and usually, BGP alone cannot be used for traffic forwarding. With EVPN, we shall see how we can get around this. BGP uses 16-bit AS numbers to define devices inside the single Autonomous System (AS) and uses the peer AS to connect other AS. A new RFC expands the ASN to 32-bit; however, for MP-EVPN, the recommendation is to stick with a 16-bit ASN.
BGP is a reachability protocol, not a routing protocol in the classic sense but rather IP prefix reachability between different AS.
BGP comes in two flavors. eBGP is BGP peering between different AS numbers, and iBGP looks inside the same AS. BGP peering must have an established neighbor and the next-hop route to the prefix, or the prefix will not be in the BGP routing table or the BGP updates sent to its neighbors. This is an important concept to remember.
BGP-4 was first created to carry only IPv4 addresses and is the original BGP. RFC 2283 defined MP-BGP in the late 1990s, then further refined in RFC 4760 and RFC 2545. These RFCs proposed the ability to add address family extensions into the BGP update packet to support IPv6, MPLS VPNV4 and VPNv6, and IPv4 and IPv6 Multicast.
We are particularly interested in the structure of the VPNv4 update and the use of route distinguisher and route targets in MPLS. The Route Distinguisher (RD) defines which VPN a route belongs to make it globally unique. The Route Target (RT) allows routes to be imported and exported from the VRF's RIB on the router's MP-BGP EVPN routing table.
MP-BGP Best Practices
- leaves spines in a given fabric must be in a single AS. For simplicity, they can all be in the same AS. In other designs, leaf pairs with MLAG or vPC can be in their own AS. This is more granular and harder to configure and manage, especially if you want to use the RT import-export function to segment. However, it is better overall for troubleshooting and segmentation; just be aware of the management complexity.
- Use the 2-byte AS range of 64512-65535. Some Vendors support the 4-byte AS range of 4200005632-4202067294, but this may prevent interop with other vendors.
- All Leaf and spine peering for the underlay must use a point-to-point link. Also, use BFD for faster convergence.
- For the EVPN address family peering, use the loopback of the BGP process. This loopback MUST be advertised into the underlay for reachability.
- EBGP-multihop of 3 is necessary for the EVPN address family peering to remain up in case of MLAG failure.
- Use next-hop-unchanged on the spines, so the next hop is the leaf pairs, not the spines.
- A minimum of a 4-node spine is recommended for best redundancy and ECMP hashing. Do not use an odd number of spines, as there are ECMP hashing issues using an odd number of spines.
- Use BGP peer groups to reduce configuration complexity if the vendor's OS supports it.
- For best vendor interop or normalization, use the RD in an ip.addr:VNI format and the BGP process loopback for IP.addr. Ex 1712.17.0.70:10100 this is the BGP loopback:VNI that you want to send in the MP-BGP update. Using the unique BGP loopback ensures the RD is unique in the fabric.
- For best vendor interop or normalization, use the RT in the ASN:VNI format described in RFC 8365. Ex 65002:10100, the ASN would be the leaf pair or all leafs in the simple design.
MP-BGP EVPN
We have come a long way with BGP, and the last piece to put it all together is the IETF extensions to MP-BGP defining EVPN. EVPN has 3 IETF extensions, 7432, the original EVPN extension for metro and WAN extension of L2, RFC 7623 for provider backbone Bridging or Metro Ethernet; and RFC 8365 is data center focused and defines using MP-BGP for VXLAN and NVGRE. We can concentrate on RFC 8365 using MP-BGP EVPN and VXLAN to fix the layer two learning and flooding issues.
Why even use EVPN and VXLAN together? We can see that MP-BGP EVPN and VXLAN address all of the issues we had with using just VXLAN in the data center and fixes the shortcomings that have faced VXLAN. Also, because MP-BGP EVPN is based on open IETF standards, we could connect multiple OEM devices in a single VXLAN fabric. WWT does not recommend this due to configuration differences, code trains, and feature sets.
A closer inspection of RFC 8365, we can leverage the new L3 Spine-Leaf designs of modern data centers as the underlay for scale and resiliency, then leverage RFC 7348 VXLAN as the Data-Plane to transport L2 and L3 traffic between VTEPs using VXLAN. Then using RFC 8365 EVPN in the Control Plane, we can advertise the MAC/IP of hosts using MPLS-based RD/RT concepts, offering accurate real-time endpoint information advertised via RFC 8365 BGP extensions.
In the example below, we have two customers, Customer_A and Customer_B. The RD (Route-Distinguisher) makes the update unique to the VRF, while the RT allows us to import and export routes and control that if we choose. We could filter EVPN routes updated by not importing or exporting routes, but we typically import and export the route targets (RT). The RD and RT use BGP extended communities, which we discussed earlier. The concept of RT and RD are carried over into MP-BGP EVPN to allow for the segmentation and filtering of segments or tenants.
Now that we understand underlays, overlays, VXLAN encapsulation/decapsulation, VTEPs, MP-BGP, and EVPN, the last piece to put it together.
MP-BGP EVPN VXLAN-putting it all together
As we defined earlier, Ethernet Virtual Private Network (EVPN) is a Layer 2 VPN technology that extends Layer 2 Ethernet segments over a Layer 3 private network. MP-BGP EVPN routes are propagated and fall into various categories. Please be aware that not all vendors that support EVPN support all of the route types below;
If we look at the diagram below, we can dissect the fields in the BGP update sent and received by the leafs. The updates will be shown as the Type from the table above. For instance, a Type 2 route will include the mac and /32 host IP address, the VTEP it was learned. The first thing to notice is the VRF in the update. The vrf is used for segmenting or tenancy in the fabric. Next is the Route Descriptor or RD. The RD must be unique in the material. The Route Target or RT becomes an exceptional value of the route types. RT can be used for import-export rules and is another way to segment an EVPN fabric. The VPN family, in this case, is EVPN.
A typical output from an EVPN routing table would look similar to the below command line output. We can see the Route Distinguisher (10.100.100.2:33872), the L2VNI (110500 and 110600), the Next Hop (VTEP), the MAC addresses, and the IP addresses of the hosts. Remember these MAC and IPs are reachable via the Next Hop, the VTEP of that leaf switch. We then encapsulate with VXLAN and route to the Next Hop in the MP-BGP EVPN table.
Putting it all together
If we now use everything we have learned, we can dissect this complicated topic and diagram reasonably quickly:
LeafFirst, we used BGP or OSPF on the P-P links between the spine and Leaf to establish our underlay neighbors with BGP or OSPF, then advertised the loopback and the VTEP loopback into the underlay. We then create the VTEPs only on the leafs, bind them to a separate loopback (typically Lo1.), and configure VXLAN bridging and routing. The underlay configuration gives us full routing to all critical interface IP addresses needed. This BGP or OSPF underlay allows ECMP reachability and 50ms failover to the Router-ID and VTEP loopbacks.
Once we have established a stable underlay for reachability, we use the MP-BGP address family extensions to create EVPN neighbors for the EVPN overlay. One important thing to note is that we use the BGP Router-ID to create the MP-BGP EVPN neighbor sessions and need the BGP multihop of 3 for reachability if we lose a leaf in an MLAG or vPC pair. We leverage the P-P links and ECMP underlay for scale and redundancy.
With MP-BGP in place, the MP-BGP EVPN routing table populates with the connected MAC and IP addresses, external or static IP routes, and the network SVIs in the fabric and then advertises it into the MP-BGP EVPN updates to all switches. We no longer need to rely on flooding or controllers to do our MAC lookups as each Leaf has the MP-BGP EVPN routing information; now, we can ROUTE layer two frames encapsulated in VXLAN using this BGP reachability info. BUM traffic is still needed; in most new switches, Head End Replication (HER) is typically used for that. Arp caching can also help with most of that BUM traffic, and minimal traffic will be flooded in a modern EVPN fabric. When Host A wants to talk with Host B, the local mac table is inspected, then the BGP EVPN routing table and the arp cache are first checked. Traffic is sent locally to a switch port, or a remote VTEP learned from EVPN or the arp cache using VXLAN encapsulation and routing; if no route or cache is found, it is flooded. Once we break down the pieces, we see that MP-BGP EVPN VXLAN is not that complicated to learn.
In conclusion, MP-BGP EVPN VXLAN is a powerful network technology that provides scalable and efficient network virtualization. While it can be complex to set up, its benefits make it a worthwhile investment for organizations looking to improve their network infrastructure. As a beginner, starting with the basics and gradually building up your knowledge through resources such as documentation, online tutorials, and networking communities is essential building.